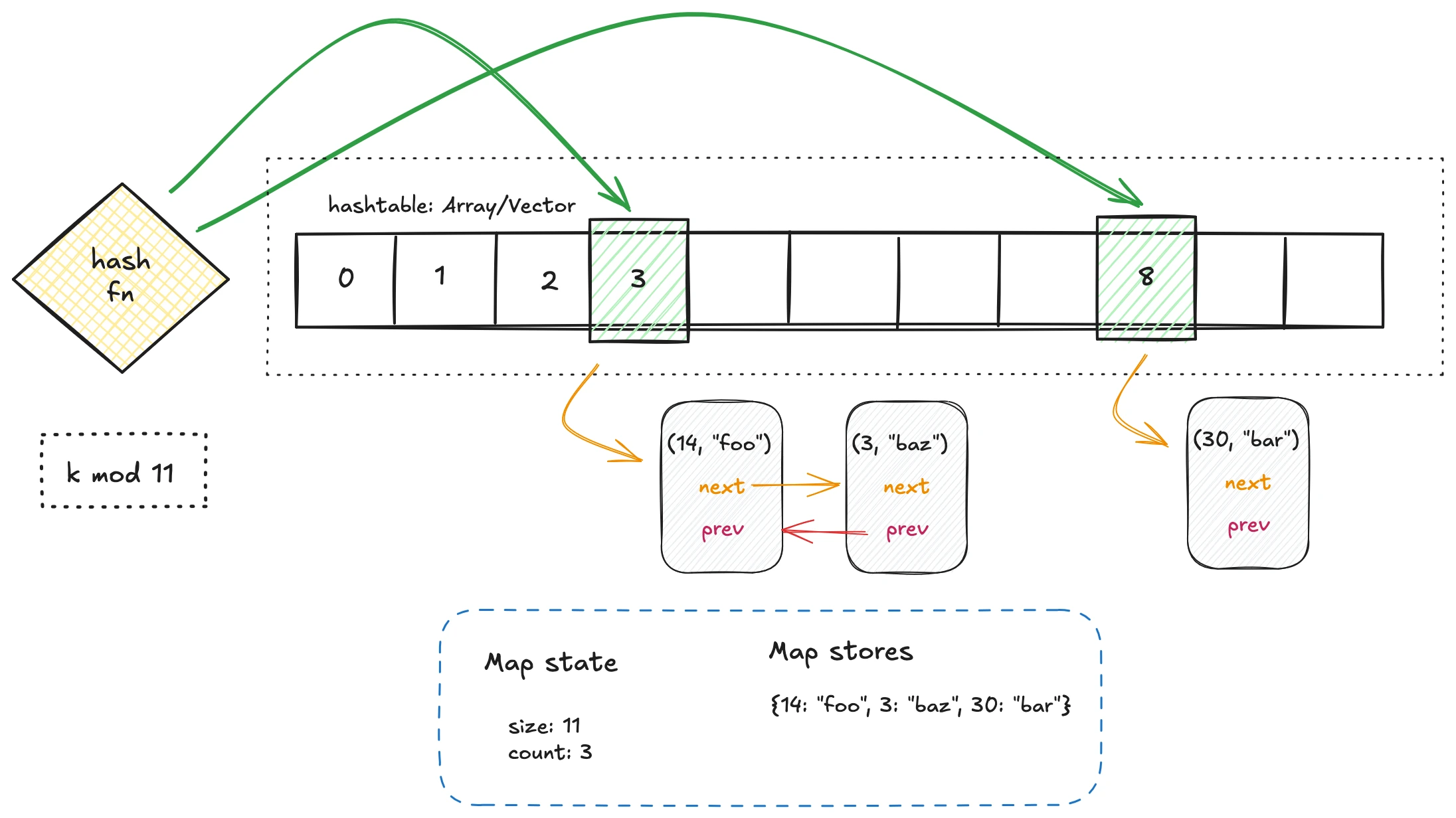
In the last article, we explored chaining, where collisions are resolved by attaching an external structure—typically a doubly linked list—to each bucket. This works, but it comes with a hidden cost. Linked lists scatter elements across the heap, turning each lookup into a sequence of random memory accesses. That destroys much of the performance advantage that arrays (or vectors) usually give us: tight, contiguous storage and cache efficiency.
Open addressing flips this philosophy on its head. Instead of pushing collisions outward into auxiliary structures, it insists that every key-value pair must live inside the array itself. No lists, no nodes, no extra indirection. At first glance, this seems elegant—one flat array, no messy pointers. Even better, the memory layout is cache-friendly, and linear scans often outperform linked structures despite doing “more work.”
But this internal simplicity comes with its own challenges. Once you commit to storing everything in the array, you now need careful strategies for:
- Probing: how to find the next open slot when a collision occurs.
- Deletion: how to remove elements without breaking probe chains (the infamous tombstone problem).
- Load management: how to keep the table from getting too crowded, since performance degrades rapidly as it fills.
In other words: open addressing hash tables offer elegance and speed in the best case, but force us to wrestle with subtleties in the worst.