Time-Traveling Through Data
What if a key could remember its entire past? Explore how append-only history, binary search, and tombstones combine to build a versioned key-value store — and why the same ideas power MVCC databases and distributed systems.
Most key-value stores are introduced as simple overwrite-based systems:
- write a value for a key,
- read the latest value back.
But many real systems cannot afford to lose history.
Imagine a bank customer disputing an overdraft fee from three weeks ago. To investigate, the bank needs to reconstruct the exact account state at a specific point in time. One approach is to start from a known balance snapshot and replay all transactions leading up to the disputed event.
Or consider collaborative editors like Google Docs, Overleaf, or Docusign. These systems allow users to inspect older revisions, restore previous states, and understand how a document evolved over time. Underneath the UI, the system needs a way to answer questions like:
- What did this object look like at version 42?
- What was the latest state before timestamp T?
- When was this value deleted or changed?
These are fundamentally versioned data access problems.
Versioned key-value stores provide a surprisingly elegant foundation for solving them. At their core, they extend the traditional key-value model by preserving historical state instead of overwriting it. That small shift unlocks powerful capabilities:
- historical reads,
- time-travel queries,
- rollback,
- auditability,
- snapshot reconstruction.
In this article, we will build a simple append-only versioned key-value store in Python and gradually evolve it toward ideas used in real storage systems such as MVCC (Multi-Version Concurrency Control) databases and LSM-tree based engines.
Modeling History as an Append-Only Log #
When building a versioned key-value store, there are several design choices we could make. One of the most important is how we represent history.
A common approach used in many systems is to treat history as append-only: instead of modifying older values, every change is recorded as a new version.
This has important consequences beyond implementation simplicity.
Consider the earlier example of a disputed overdraft fee. To reconstruct the account balance at a specific point in time, we can replay transactions from an earlier known state until we reach the reference timestamp. Since historical entries are preserved, investigators can trace exactly how the balance evolved over time.
Now imagine a different design where older versions were edited in place after a reconciliation system detected an internal error. The latest balance may become correct, but the system loses an important property: explainability. A case officer may discover that the fee was incorrect, but would no longer be able to meaningfully reconstruct why it happened or what the system previously believed to be true.
Append-only history preserves more than data — it preserves causality.
Another design choice is how versions themselves are assigned.
In this implementation, we use a single global version counter shared across all keys:
self._put_version += 1
This introduces a globally ordered history into the system.
For example:
PUT(user_balance, 100) -> v1
PUT(document_title, "Draft") -> v2
PUT(user_balance, 120) -> v3
Even though the writes affect unrelated keys, the system can still determine which write happened before another.
This property is known as total ordering.
Total ordering simplifies many operations:
- replaying events,
- reconstructing snapshots,
- debugging state transitions,
- and reasoning about causality across entities.
An alternative design would maintain versions independently for each key:
user_balance: v1, v2, v3
document_title: v1, v2
This removes the need for a globally coordinated counter and scales more naturally in distributed systems, but also loses the ability to establish ordering between unrelated keys.
For our implementation, we will choose the simpler globally ordered model.
At its core, the data structure is surprisingly small:
from collections import defaultdict
class KVStore:
def __init__(self):
self._put_version = 1
self.store = defaultdict(list)
def put(self, key: str, value: object) -> int:
self.store[key].append((value, self._put_version))
version = self._put_version
self._put_version += 1
return version
Each key maps to a list of (value, version) pairs.
A sequence of writes like:
PUT("balance", 100)
PUT("balance", 150)
PUT("balance", 120)
would internally look like:
balance:
[(100, v1), (150, v2), (120, v3)]
Since newer entries are always appended, retrieving the latest value becomes trivial:
def get(self, key: str) -> Optional[object]:
if key not in self.store:
return None
return self.store[key][-1][0]
The more interesting operation is historical lookup: finding the value associated with the largest version less than or equal to a requested version.
Our first implementation uses a linear scan starting from the newest value and moving backward through history:
def get_with_version_linear(
self,
k: str,
version: int
) -> Optional[object]:
if k not in self.store:
return None
values = self.store[k]
i = len(values) - 1
while i >= 0 and values[i][1] > version:
i -= 1
if i < 0:
return None
return values[i][0]
This works because entries are naturally ordered by insertion time.
The implementation is simple, but it also reveals an important property of append-only structures: historical data is already sorted by version. That observation will later allow us to replace the linear scan with a much more efficient binary search.
I would like to make a remark that on the surface our implementation resembles linked hashmaps. Both share some key features:
- Both use a hash map where each key points to a list/chain of nodes
- Both store multiple entries per key
In a linked hashmap, chaining is a workaround — ideally each bucket holds one entry. Here, the list is intentional. History accumulating is the feature, not a collision to be resolved.
Optimizing Historical Lookups #
Our initial implementation used a linear scan to retrieve historical values. Starting from the newest version, we walked backward until we found the largest version less than or equal to the requested version.
That approach is simple and surprisingly effective for small histories, but it eventually becomes expensive as the number of versions grows.
Fortunately, our append-only design gives us an important property for free: versions are naturally ordered.
[(10, v1), (15, v3), (22, v7), (30, v12)]
Since newer writes always receive larger versions, historical entries are already sorted. This allows us to replace the linear scan with a binary search and reduce lookup complexity from:
O(N) -> O(log N)
The optimization itself is fairly small:
def get_with_version(
self,
k: str,
version: int
) -> Optional[object]:
"""
Return value for largest version <= requested version
"""
if k not in self.store:
return None
values = self.store[k]
l, r = 0, len(values) - 1
result = None
while l <= r:
mid = (l + r) // 2
if values[mid][1] <= version:
result = values[mid][0]
l = mid + 1
else:
r = mid - 1
return result
The key idea is subtle but important.
We are not searching for an exact version match. Instead, we want:
the newest value whose version is still less than or equal to the requested version.
For example:
[(10, v1), (15, v3), (22, v7)]
GET @v5 -> 15
Even though version v5 does not exist, the system can still reconstruct the correct historical state by using the latest version visible at that point in time.
This optimization works because our implementation guarantees a globally ordered sequence of versions.
In this article we used a single global version counter:
self._put_version += 1
This introduces a total ordering across all writes in the system.
However, globally coordinated version assignment can become expensive in distributed systems. As systems scale, many implementations relax this constraint and adopt alternative ordering strategies:
- per-key or per-partition versioning,
- logical timestamps,
- Lamport clocks,
- hybrid logical clocks (HLCs),
- or globally synchronized timestamps like TrueTime in Google Spanner.
Each approach makes different tradeoffs between scalability, coordination overhead, and the ability to reason about causality across the system.
For our implementation, a globally ordered counter keeps the model simple while still exposing many of the ideas used in real storage systems.
Deletion and Tombstones #
So far, our implementation only supports inserting and reading values. Deletion turns out to be more interesting than it initially appears.
The moment we introduce DELETE, we must answer an important question:
Should deletion erase history?
Physical deletion removes data entirely:
DELETE key1
After deletion, there is no trace that the value ever existed.
Logical deletion takes a different approach. Instead of removing history, the system records that the key was deleted at a specific version.
Many storage systems implement this using tombstones.
[v1:10] -> [v5:20] -> [v9:TOMBSTONE]
This preserves historical reconstruction:
| Query | Result |
|---|---|
| GET @v6 | 20 |
| GET latest | NULL |
This distinction matters in real systems:
- accidental deletions can be recovered,
- replication systems can propagate deletions safely,
- and historical state remains reconstructable.
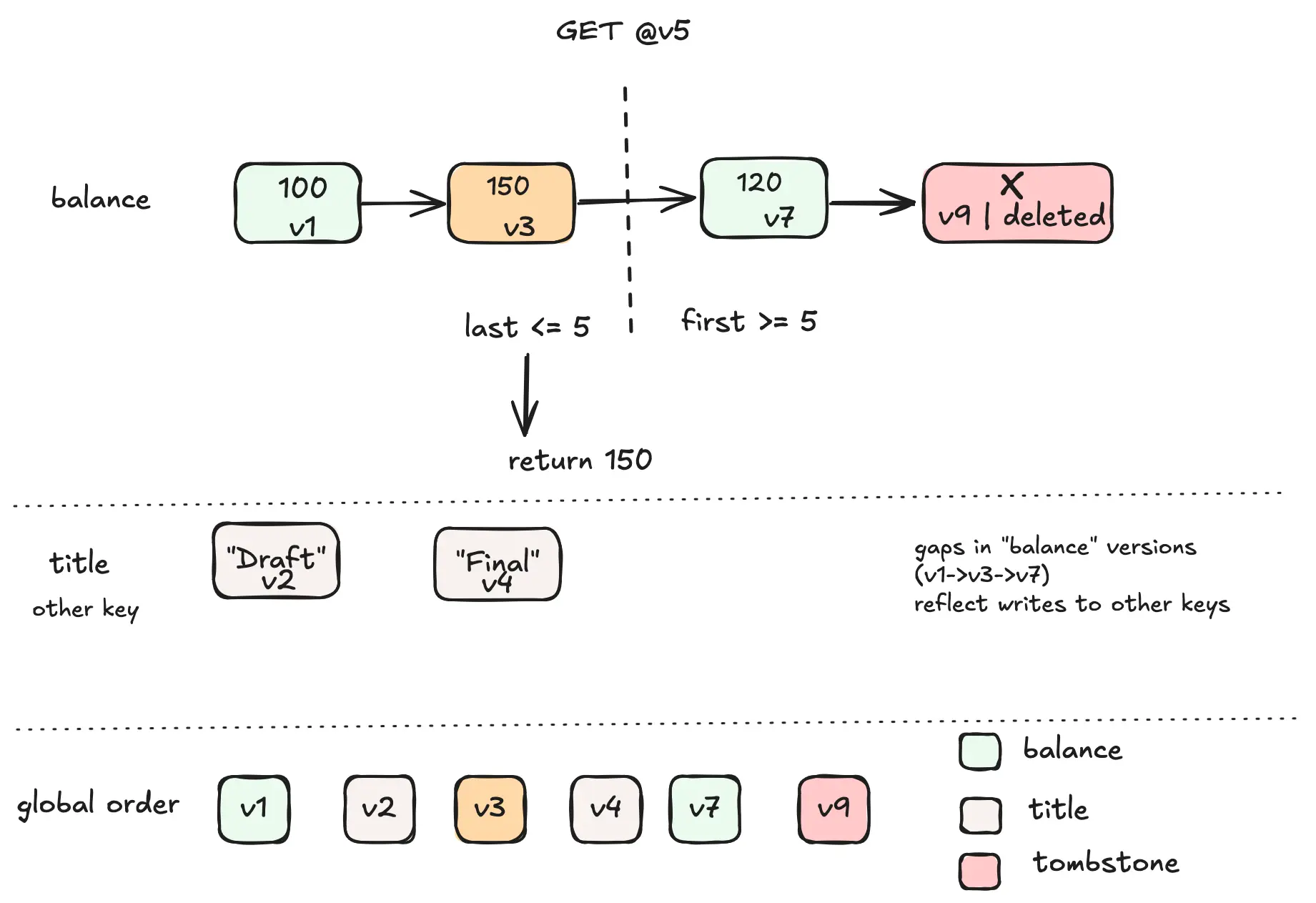
Diagram illustrating versioned KV store internal state
Tombstones are widely used in systems such as Cassandra, LSM-tree based storage engines, and distributed databases.
Internally, tombstones are implementation details. Consumers of the API should observe normal deletion semantics rather than interacting with tombstone markers directly.
A simple implementation can use a unique sentinel object:
_TOMBSTONE = object()
Deletion then becomes another append-only write:
def delete(self, key: str) -> bool:
if key in self.store:
self.put(key, _TOMBSTONE)
return True
return False
The get operation must now interpret tombstones as missing values:
def get(self, key: str) -> Optional[object]:
if key not in self.store:
return None
value = self.store[key][-1][0]
return value if value != _TOMBSTONE else None
The same adjustment must also be applied to historical lookups in get_with_version.
Once again, append-only history keeps the implementation surprisingly small. Even deletion becomes another immutable event in the timeline rather than destructive mutation of state.
Conclusion #
At first glance, a versioned key-value store feels like a small extension over a normal dictionary: instead of storing a single value for a key, we store a history of values.
But that single shift in perspective introduces many of the ideas that appear in real storage systems.
In this implementation we explored:
- append-only history,
- globally ordered versions,
- historical reconstruction,
- binary search over immutable history,
- and logical deletion using tombstones.
None of these ideas are individually complicated. Yet when combined, they allow the system to answer questions far beyond simple key lookups:
"What did the system believe at version v42?"
That ability to reconstruct historical state is foundational to many real-world systems:
- databases implementing MVCC,
- audit and compliance systems,
- collaborative editing platforms,
- event-sourced architectures,
- and distributed storage engines.
One of the most interesting aspects of systems design is that sophisticated behavior often emerges from layering small, composable ideas together. Versioned key-value stores are a good example of this. The implementation itself is relatively compact, but it naturally leads into much deeper topics:
- transaction isolation,
- snapshot reads,
- commit protocols,
- TTL and data expiration,
- storage compaction,
- write-ahead logging,
- LSM trees,
- and MVCC-based concurrency control.
In future iterations, we can evolve this simple implementation further by introducing concepts like transactions, snapshot isolation, or background compaction to manage growing historical state.
For now, the important takeaway is not the specific implementation details, but the underlying design philosophy:
preserve history, maintain ordering, and reconstruct state when needed.
Many systems operating at massive scale are ultimately built on surprisingly small ideas applied consistently over time.