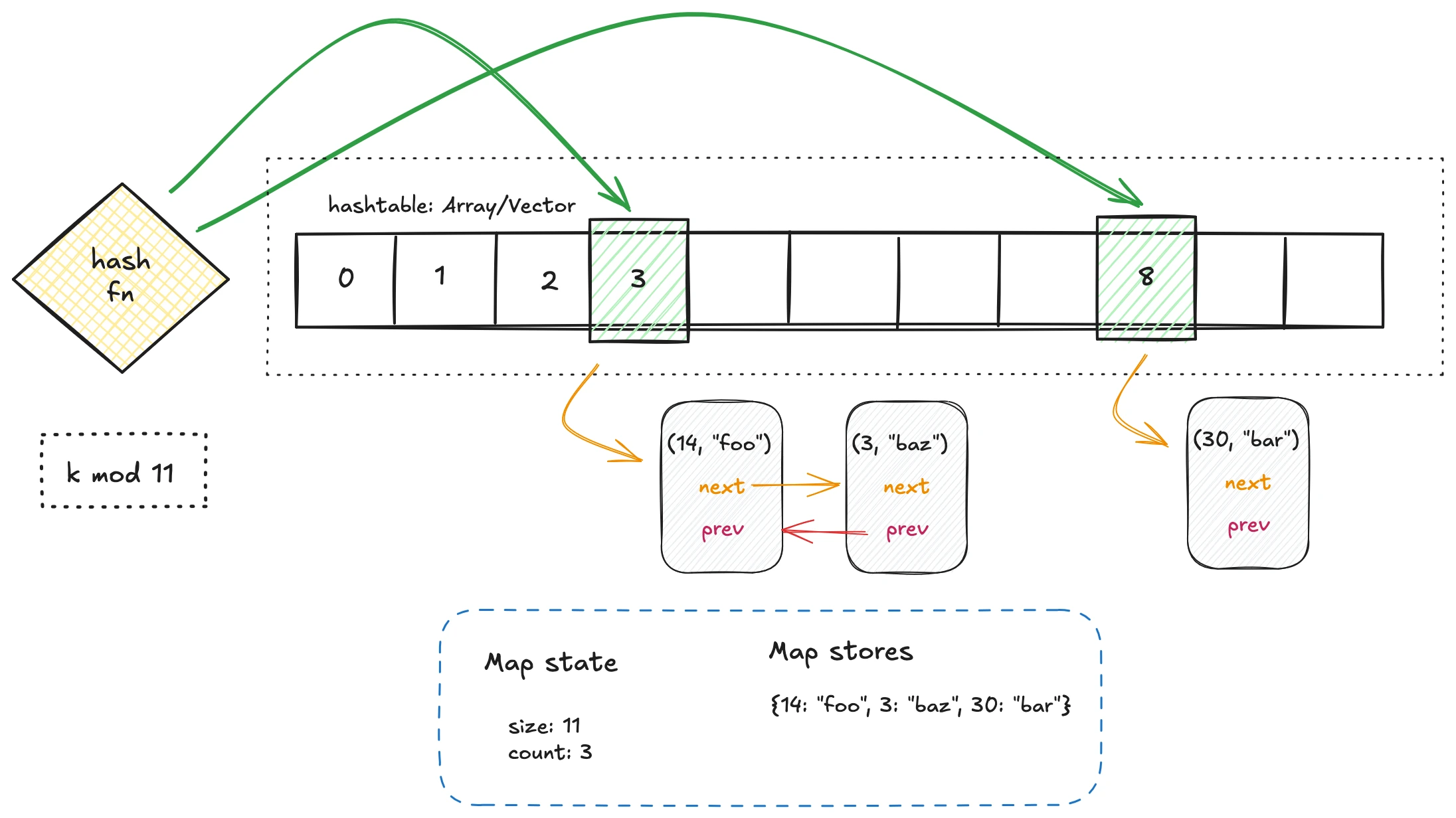
Most key-value stores are introduced as simple overwrite-based systems:
- write a value for a key,
- read the latest value back.
But many real systems cannot afford to lose history.
Imagine a bank customer disputing an overdraft fee from three weeks ago. To investigate, the bank needs to reconstruct the exact account state at a specific point in time. One approach is to start from a known balance snapshot and replay all transactions leading up to the disputed event.
Or consider collaborative editors like Google Docs, Overleaf, or Docusign. These systems allow users to inspect older revisions, restore previous states, and understand how a document evolved over time. Underneath the UI, the system needs a way to answer questions like:
- What did this object look like at version 42?
- What was the latest state before timestamp T?
- When was this value deleted or changed?
These are fundamentally versioned data access problems.
Versioned key-value stores provide a surprisingly elegant foundation for solving them. At their core, they extend the traditional key-value model by preserving historical state instead of overwriting it. That small shift unlocks powerful capabilities:
- historical reads,
- time-travel queries,
- rollback,
- auditability,
- snapshot reconstruction.
In this article, we will build a simple append-only versioned key-value store in Python and gradually evolve it toward ideas used in real storage systems such as MVCC (Multi-Version Concurrency Control) databases and LSM-tree based engines.